How Website Structures Impact the Success of Data Scraping Projects
The structure of a website can make or break your data scraping project. A well-organized site offers clear paths to valuable information, while a chaotic layout can hinder your efforts. Embrace thoughtful design; it empowers efficient data extraction and fuels your success!
In the digital age, where information is the new currency, the ability to extract valuable data from websites has become a game changer for businesses and researchers alike. Yet, the success of data scraping projects often hinges not just on the tools and techniques employed, but significantly on the very structure of the websites being targeted. Understanding how website structures influence data scraping can transform a challenging endeavor into a seamless, productive journey. Imagine harnessing the power of data with precision and efficiency—unlocking insights that fuel innovation and drive strategic decisions. In this article, we will explore the pivotal role of website architecture in shaping data scraping success, equipping you with the knowledge to navigate the complexities of the web. Join us as we uncover the secrets to turning intricate web designs into powerful data goldmines, empowering you to elevate your projects to new heights of effectiveness and clarity. Let’s embark on this journey together, and revolutionize the way you approach data extraction.
Understanding the Framework of Successful Data Scraping Ventures
In the realm of data scraping, an acute understanding of website structures is indispensable. The architecture of a site significantly influences the efficacy of scraping efforts, shaping both the tools employed and the strategies devised. By delving into the intricacies of HTML, CSS, and JavaScript, data scrapers can unlock the treasure trove of information that lies within seemingly unyielding surfaces.
Identifying Key Elements: A successful scraping venture begins with recognizing the critical components of a website’s framework. Pay attention to:
HTML Tags: Essential for locating and extracting data accurately.
CSS Selectors: Useful for targeting specific elements, ensuring that you gather only the most relevant information.
JavaScript Rendering: Many modern websites rely on dynamic content; hence, understanding AJAX requests can be a game-changer.
Navigating Different Structures: Websites are often built using various frameworks, from simple static pages to complex single-page applications (SPAs). Each type presents unique challenges and opportunities for scrapers:
Static Sites: These are usually straightforward to scrape since the content is directly embedded in the HTML.
Dynamic Sites: Here, data may be loaded asynchronously, requiring scrapers to simulate user interactions or employ headless browsers.
Content Management Systems (CMS): Familiarizing yourself with popular CMS architectures can streamline the scraping process.
Data Extraction Techniques: Once the structure is understood, the next step involves choosing the right extraction technique. Depending on the site’s complexity, you might opt for:
XPath Queries: For precision in targeting specific nodes in the XML structure.
Regular Expressions: Useful for pulling data that follows a particular pattern.
API Utilization: Many websites offer APIs that can significantly reduce scraping efforts by providing data in a structured format.
Building a Robust Framework: The success of a data scraping project hinges not only on understanding the website’s structure but also on developing a resilient framework capable of adapting to changes. Consider implementing:
Error Handling: To ensure that your scraper can recover from unexpected changes in the website structure.
Scalability: Design your scraping solution to handle multiple pages or even entire sites seamlessly.
Data Storage Options: Choose formats that facilitate easy data analysis, such as CSV, JSON, or direct database entries.
a thorough comprehension of website structures is paramount to the success of data scraping initiatives. By mastering the nuances of HTML, CSS, and JavaScript, and employing tactical extraction methods, you can transform potential obstacles into stepping stones for your scraping ventures.
The Significance of a Well-Organized Website Structure
A well-organized website structure serves as the backbone of any successful data scraping project. When a website is thoughtfully arranged, it not only enhances the user experience but also significantly improves the effectiveness of data extraction tools. The clarity of navigation and the logical flow of information make it easier for web scrapers to find and gather relevant data efficiently.
Consider the following key elements that contribute to an effective website structure:
Hierarchical Organization: A clear hierarchy allows web scrapers to understand the relationships between different sections, making it simpler to target specific content.
Consistent URL Patterns: Uniform URL structures help scrapers predict where to find certain data, reducing the time and effort required for scraping tasks.
Logical Categorization: Well-defined categories and tags enable scrapers to filter and retrieve data based on relevant topics efficiently.
Responsive Design: A mobile-friendly design ensures that data can be accessed seamlessly across different devices, facilitating comprehensive scraping.
Furthermore, an organized website structure can dramatically reduce the likelihood of encountering common scraping challenges, such as:
Broken links that hinder data access
Inconsistent data formats that complicate extraction
Hidden or dynamically-loaded content that is difficult to retrieve
To illustrate the impact of website structure, consider the following comparison:
Website Structure Type
Scraping Efficiency
Ease of Data Retrieval
Well-Organized
High
Simple
Poorly Organized
Low
Complex
investing time in creating a well-structured website can yield significant returns for data scraping projects. By ensuring that the website is easy to navigate and logically arranged, you not only facilitate more effective data extraction but also set the stage for future growth and success. Ultimately, a thoughtfully designed structure aligns your website with the goals of your scraping initiatives, transforming potential hurdles into opportunities for streamlined efficiency.
Navigating the Maze: How URL Hierarchies Influence Data Accessibility
In the realm of data scraping, the architecture of a website plays a pivotal role in determining how effectively data can be accessed and extracted. A well-structured URL hierarchy not only enhances user experience but also simplifies the data scraping process. By understanding the intricacies of URL structures, data analysts and developers can navigate the labyrinth of web pages with greater ease and efficiency.
Consider the following key factors that influence data accessibility:
Logical Hierarchy: Websites that employ a clear and logical hierarchy allow scrapers to follow a predictable path. This means that data can be located without extensive crawling, saving time and resources.
Consistent Naming Conventions: URLs that maintain consistency in naming conventions reduce the likelihood of errors during scraping. When URLs are intuitive and descriptive, machines can easily identify relevant data points.
Use of Parameters: While parameters can add complexity, they can also provide targeted data. Understanding how parameters work enables scrapers to efficiently filter through vast datasets without unnecessary data retrieval.
The effectiveness of a scraping project can also be improved through the use of a structured approach. For instance, employing a systematic method of categorizing data can enhance the quality of information extracted. An organized table format can be beneficial for visualizing the scraped data:
Data Type
Accessibility Level
Example URL
Product Info
High
example.com/products/item123
Blog Posts
Medium
example.com/blog/post-title
User Profiles
Low
example.com/users/profile?id=456
Moreover, implementing a strategic approach when defining scraping targets can significantly amplify the effectiveness of the project. Focusing on high-traffic areas of a website, such as landing pages or product categories, can yield higher quality data. Additionally, understanding the relationship between different pages through their URL structure can uncover hidden insights within the data.
Ultimately, the connection between URL hierarchies and data accessibility cannot be overstated. As the complexity of websites continues to grow, so too does the necessity for scrapers to adapt and evolve. By embracing best practices in URL structure and employing sophisticated scraping techniques, data professionals can turn the daunting maze of web data into a treasure trove of valuable insights.
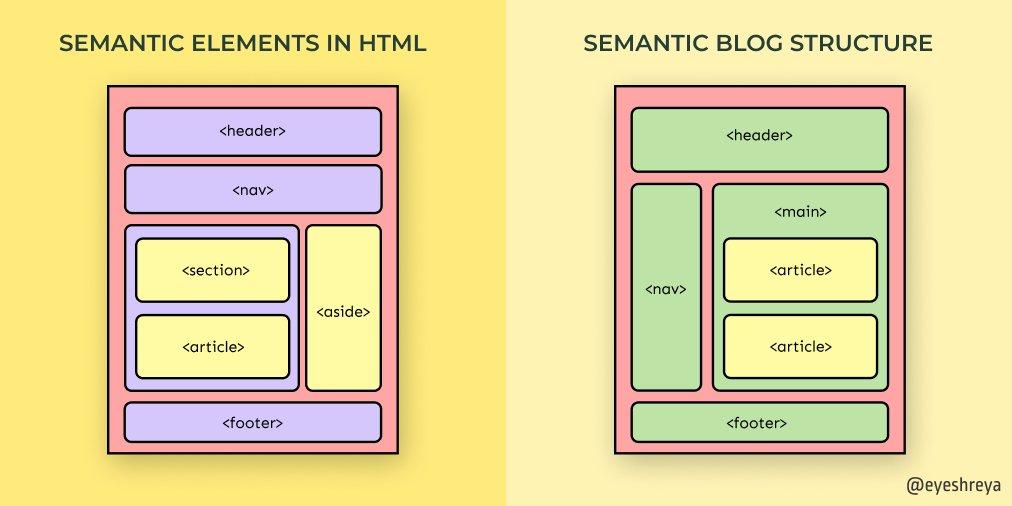
The Role of HTML Semantics in Enhancing Data Extraction Efficiency
In the realm of data scraping, the structure and presentation of a website can significantly influence the efficiency of data extraction. By utilizing HTML semantics effectively, website developers enable scrapers to identify and interpret data more accurately. This not only streamlines the extraction process but also enhances the quality of the data retrieved.
When semantic HTML elements are employed, such as
, , and , they provide clear context about the content’s purpose. This clarity allows scrapers to:
Quickly locate relevant data: Semantic tags help scrapers quickly isolate the information they need without sifting through irrelevant content.
Understand relationships between elements: Clear hierarchies and relationships make it easier to navigate and extract complex data structures.
Reduce errors: Well-structured HTML minimizes the risk of misinterpretation, leading to cleaner, more accurate datasets.
Moreover, when websites implement microdata and schema.org annotations, they further enhance the semantic value of their content. This additional layer of metadata provides scrapers with context-rich information, facilitating more intelligent data extraction and allowing for:
Better categorization: Data scrapers can classify and organize extracted data more efficiently.
Improved usability: Contextual information enhances the usability of scraped data, making it more valuable for analysis and application.
To illustrate the impact of semantic HTML, consider the following table comparing two hypothetical websites: one utilizing semantic elements and the other relying on generic tags.
Website Structure
Data Extraction Efficiency
Data Quality
Site A (Semantic)
High
High
Site B (Generic)
Low
Medium
This example clearly demonstrates how the choice of HTML semantics directly correlates with the success of data scraping projects. Websites that prioritize semantic structure are not only beneficial for users but also for developers and data professionals striving for efficiency and accuracy in their data collection initiatives.
Designing for Success: The Importance of Mobile-Friendly Structures
In today’s digital landscape, the success of any data scraping project hinges on the website’s structure, particularly its mobile-friendliness. With a significant portion of web traffic coming from mobile devices, it’s crucial to recognize that a well-designed, responsive site not only enhances user experience but also facilitates effective data extraction.
When a website is optimized for mobile, it typically incorporates:
Responsive Design: Adapts seamlessly to different screen sizes, ensuring that content is accessible regardless of the device.
Fast Loading Times: Mobile-friendly sites load quickly, reducing bounce rates and allowing scrapers to collect data efficiently.
Clear Navigation: Simplified menus and navigation elements enhance user interaction and make it easier for scraping tools to traverse the site.
The architecture of a mobile-friendly site often reflects best practices that translate directly into better data scraping outcomes. For instance, websites that adhere to semantic HTML5 structures allow scrapers to understand content hierarchies more effectively. This clarity can be crucial in pulling accurate data segments, especially when dealing with complex datasets.
Furthermore, a clean and logical URL structure is pivotal. Short, descriptive, and keyword-rich URLs not only improve SEO but also facilitate easier scraping. Consider the following table that highlights the impact of URL structure on data extraction:
URL Format
Scraping Efficiency
/products/12345
High
/category.php?id=12345
Low
Moreover, mobile-friendly websites tend to implement structured data markup, which can significantly aid scraping efforts. By providing explicit information about content types, schemas guide scrapers to locate and extract data with precision. This structured approach not only enhances the quality of collected data but also leads to faster processing times, empowering projects to deliver insights more rapidly.
Ultimately, embracing a mobile-friendly design is not just a trend; it’s a strategic advantage that can elevate the effectiveness of data scraping initiatives. Successfully navigating the intricacies of a well-structured, responsive website can open doors to richer datasets and more reliable outcomes. Organizations that prioritize mobile optimization will find themselves better equipped to harness the power of data, turning information into actionable strategies for growth.
Leveraging Site Maps for Streamlined Data Collection
Harnessing the power of site maps can significantly enhance the efficiency of your data scraping endeavors. A well-structured site map serves as a blueprint for your web scraping projects, guiding your data extraction efforts with precision and clarity.
When you utilize site maps effectively, you can:
Identify Key Data Points: Site maps help pinpoint where valuable information resides within a website, allowing you to focus your scraping efforts on the most relevant sections.
Optimize Crawl Paths: By understanding the layout of a website, you can design more efficient crawl paths that minimize unnecessary requests and reduce load times.
Avoid Duplicate Data: Site maps can reveal duplicate content or pages, enabling you to filter out redundant data during your scraping processes.
Enhance Data Accuracy: A clear view of the website’s structure allows you to map out relationships between different data points, leading to more accurate and comprehensive datasets.
Moreover, with the rise of dynamic content, leveraging site maps becomes even more crucial. They can help you adapt your scraping strategies to accommodate the changing layouts and structures of modern web pages. Additionally, understanding how a site organizes its information helps you determine the best tools and techniques for efficient data extraction.
Consider a simple table showcasing how different site map structures can influence data scraping efficiency:
Site Map Structure
Impact on Scraping
Hierarchical
Facilitates organized data collection, making it easier to navigate content relationships.
Flat Structure
Increased risk of missing data; requires more extensive crawling to cover all areas.
Dynamic Sitemap
Allows adaptability to content changes, ensuring ongoing data accuracy.
the strategic use of site maps not only streamlines the data collection process but also empowers you to derive meaningful insights from the information you gather. Embracing this approach can transform your scraping projects from mere data retrieval into impactful information acquisition.
Decoding JavaScript-Heavy Websites for Effective Scraping
In the ever-evolving landscape of web development, JavaScript-heavy websites present both challenges and opportunities for data scraping projects. As more developers utilize JavaScript frameworks like React, Angular, and Vue.js, the way content is rendered on these sites has transformed significantly. Unlike static websites, these dynamic platforms often load data asynchronously, making traditional scraping methods less effective.
To navigate this complexity, it’s essential to understand the underlying structure of a JavaScript-driven website. Here are some key components to consider:
Dynamic Content Loading: Many sites use AJAX calls to fetch data. Understanding how and when these calls are made can lead to successful scraping.
DOM Manipulation: Familiarity with how the Document Object Model (DOM) is altered by JavaScript can help you identify when data is available and how to access it.
Client-Side Rendering vs. Server-Side Rendering: Recognizing whether a site is primarily client-rendered or server-rendered can dictate your scraping strategy.
Utilizing tools such as headless browsers or libraries like Puppeteer can greatly enhance your ability to scrape JavaScript-heavy websites. These tools render the page as a user would see it, allowing you to capture dynamically loaded content. Additionally, implementing wait strategies can ensure that your scraper pauses until the desired elements are fully loaded, minimizing the chances of missing crucial data.
Another vital aspect is understanding the site’s API endpoints. Many modern web applications communicate with backend services via well-defined APIs. By inspecting network requests in developer tools, you can often find direct links to the data you need, bypassing the need to scrape the visual layout entirely. Here’s a simple overview of common API interaction methods:
Method
Description
GET
Retrieves data from the server.
POST
Sends data to the server for processing.
PUT
Updates existing data on the server.
DELETE
Removes data from the server.
Ultimately, the success of your scraping project hinges on a thorough understanding of these techniques and an adaptive mindset. As technology evolves, so too must your strategies. By embracing the complexities of JavaScript-heavy websites and leveraging modern tools, you can unlock a wealth of data, turning challenges into triumphs.
The Impact of Page Load Speeds on Data Retrieval Success
The speed at which a webpage loads plays a crucial role in the overall success of data retrieval efforts. When scraping websites for data, every millisecond counts. If a page takes too long to load, it can lead to missed opportunities and incomplete data sets.
Consider the following implications of slow page loading on scraping projects:
Increased Timeouts: If a website is sluggish, scraping tools may time out before they can extract the needed information, resulting in data loss.
Resource Consumption: Prolonged load times can consume more bandwidth and CPU resources, potentially leading to higher operational costs.
Inconsistent Data: Slow loading times can affect the stability of the content being scraped, causing discrepancies in the retrieved data.
Moreover, the impact of load speeds extends beyond mere data collection; it influences the efficiency of the scraping process itself. A well-structured website, optimized for fast loading, can significantly enhance the scraping experience:
Optimized HTML/CSS: Websites with clean and efficient code allow scraping bots to navigate and extract data effortlessly.
Minimal Redirections: Pages that minimize unnecessary redirects contribute to faster loads, facilitating smoother data extraction.
Mobile Responsiveness: Sites designed for mobile use often load faster, providing a seamless experience for scraping tools.
This data clearly shows that as page load speeds increase, the number of successfully retrieved items decreases significantly. Therefore, for any data scraping project, investing time in optimizing the targeted website’s load speed can yield substantial benefits in terms of data quality and quantity.
In the rapidly evolving landscape of data scraping, ethical considerations take center stage, especially when it comes to respecting the intricate structures that websites employ. Every website is designed with a unique architecture that serves specific purposes and, in many cases, reflects the owner’s intellectual property. Ignoring these structures can lead to unintended consequences that go beyond legal implications, affecting relationships and reputations.
When embarking on a scraping project, it is vital to adhere to several ethical guidelines to ensure that your actions do not disrupt the balance between data availability and website integrity:
Compliance with Robots.txt: Always check the robots.txt file of the website. This file explicitly outlines which parts of the site can be accessed by crawlers and scrapers, serving as a guideline for ethical scraping.
Rate Limiting: Respect the website’s server resources by implementing rate limiting in your scraping scripts. Overloading a server with requests can lead to service interruptions, which can have a ripple effect on all users.
Attribution: When using data from a website, giving credit where it’s due not only shows respect for the original creators but also fosters a sense of community and trust within the data-sharing ecosystem.
Purpose of Data Usage: Always consider the intent behind your data scraping efforts. Utilizing data for constructive and beneficial outcomes, such as research or community enrichment, aligns with ethical practices.
Moreover, understanding the technical layout of a website can significantly enhance your scraping efficiency while minimizing ethical concerns. Websites often utilize measures like CAPTCHAs or dynamic content loading to protect their data. Being aware of these features can guide your approach, allowing you to devise solutions that align with ethical standards.
Furthermore, the concept of “data ownership” should not be overlooked. Although data may be publicly accessible, it does not automatically grant the right to use it in any capacity. Engaging with website owners for permission or clarification can help establish a mutually beneficial relationship. Remember, a collaborative approach can lead to greater data access in the long run, as many website owners are open to sharing their data if approached appropriately.
navigating the ethical landscape of data scraping requires a careful balance of technical skill and moral responsibility. By respecting website structures and adhering to established guidelines, you not only protect your scraping project but also contribute positively to the larger online ecosystem. Ethical scraping is not just a best practice; it’s a commitment to fostering a respectful and cooperative digital environment.
Optimizing Your Scraping Strategy: Tools and Techniques for Success
Understanding the layout and design of a website is crucial for the success of any data scraping project. Websites often employ different structures, which can significantly influence how effectively data can be harvested. By analyzing these structures, you can enhance your scraping strategy and maximize the data you collect.
Key Elements to Consider:
HTML Structure: Familiarize yourself with the HTML tags used on the target site. Websites often use
, , and
tags to organize content. Understanding where your target data resides within this structure will streamline your scraping process.
Dynamic Content: Many modern websites load content dynamically using JavaScript. Tools like Selenium or Puppeteer can help you capture this data in real-time, giving you access to information that might not be immediately visible in the page source.
Pagination: If the data is spread across multiple pages, strategize how to navigate through them. Implementing solutions to handle pagination effectively is essential to ensure you don’t miss critical information.
Another factor to consider is the website’s robots.txt file, which dictates what parts of the site can be accessed by scrapers. Always review this file before starting your project to ensure compliance with the site’s rules and to avoid potential legal issues.
In addition, using the right tools can significantly improve your scraping efficiency. Here’s a comparison of some popular scraping tools:
Tool
Best For
Pros
Cons
Scrapy
Large-scale projects
Highly customizable, fast
Steeper learning curve
Beautiful Soup
Small to medium projects
User-friendly, Python-based
Slower for large datasets
Octoparse
No coding required
Visual interface, easy to use
Limited free version
By recognizing how website structures impact your scraping endeavors, you can tailor your approach accordingly. This might mean selecting a different tool, adjusting the techniques you employ, or even reconsidering the data points you aim to extract. The more you understand these elements, the more successful your scraping projects will be.
Case Studies: Transforming Complex Structures into Data Goldmines
In the realm of data scraping, the structure of a website plays a pivotal role in determining the success of any project. By examining diverse case studies, we can uncover methodologies that transform intricate structures into valuable data goldmines.
One of the most notable examples is the transformation of a leading e-commerce platform. Initially, their website had a convoluted structure with nested navigation systems that made it challenging for traditional scraping methods. However, the implementation of an intelligent bot architecture that mimicked human browsing behavior allowed for successful data extraction. Key elements that contributed to this transformation included:
Dynamic Pathways: Utilizing dynamic URLs that adapt to user behavior enhanced accessibility.
API Integration: Building a robust API that provided structured data feeds reduced the need for scraping entirely.
Another compelling case is a news aggregation site known for its vast array of articles. Faced with heavy anti-scraping measures, the team redesigned their scraping approach to focus on extracting meta-data and headlines from RSS feeds. This strategic pivot not only improved efficiency but also ensured compliance with the site’s terms of service. The key takeaways included:
Feed Utilization: Leveraging available RSS feeds to collect data without raising flags.
Rate Limiting: Implementing a respectful scraping schedule to avoid IP bans.
Content Prioritization: Focusing on high-value articles that drive traffic and engagement.
Moreover, a recent project involving a travel booking site showcased the importance of adaptable scraping techniques. The website’s structure changed frequently, which could have derailed the scraping efforts. However, by employing a modular scraping framework that allowed for rapid adjustments in response to structural changes, the project yielded a consistent flow of data. Essential strategies included:
Visual Mapping: Utilizing visual tools to map site structures for easier navigation and data extraction.
These case studies illuminate a crucial insight: the fusion of technical savvy with strategic adaptability can turn any website, no matter how complex, into a treasure trove of data. By analyzing and understanding the underlying structure, teams can craft tailored scraping solutions that not only succeed but also promote sustainable practices in data management.
Future-Proofing Your Data Scraping Initiatives with Adaptive Structures
In an era where data is regarded as the new oil, ensuring the durability and adaptability of your data scraping initiatives is paramount. As web technologies evolve, so do the structures of websites, which can significantly impact the outcomes of scraping projects. To keep pace, developing adaptive structures is essential for long-term success. These structures not only withstand the test of time but also allow for seamless integration with various website paradigms.
One effective way to future-proof your scraping efforts is to implement a modular design in your scraping framework. This involves creating components that can be easily modified or upgraded without overhauling the entire system. Benefits of a modular approach include:
Flexibility: Easily adapt to changing website layouts.
Scalability: Expand scraping capabilities to cover new sites or data types without extensive rewrites.
Maintainability: Simplifies debugging and enhances team collaboration.
Incorporating machine learning into your data scraping strategy can also bolster your project’s resilience against structural changes. By leveraging algorithms that learn from previous scraping experiences, you can automate updates and adjustments. This proactive approach means your scraping tools can:
Predict changes: Analyze trends in website design to anticipate future modifications.
Adapt dynamically: Adjust scraping methods in real-time based on the content layout.
Improve accuracy: Reduce the likelihood of errors that arise from structural shifts.
Moreover, fostering a collaborative relationship with web developers can yield significant advantages. By sharing insights and challenges, you can gain valuable perspectives on upcoming website changes. This partnership can facilitate the establishment of robust APIs or structured data formats, optimizing the way you interact with web content. The table below illustrates key areas for collaboration:
Collaboration Area
Potential Outcomes
API Development
Direct access to structured data.
Content Formats
Standardized data for easier scraping.
Feedback Loops
Continuous improvement based on user experience.
keep in mind that user experience is at the heart of website design. By focusing on creating a scraping strategy that aligns with user-centric principles, you not only enhance your scraping performance but also contribute to a more holistic web ecosystem. Consider adopting ethical scraping practices, which not only ensure compliance with legal standards but also foster goodwill with site owners.
Collaborating with Developers: Enhancing Access to Data Through Structure
In the fast-paced world of data scraping, collaboration with developers can significantly enhance how we access and utilize information. The structure of a website is not merely a technical aspect; it serves as the backbone of how data can be extracted efficiently. When developers understand the intricacies of both the website’s layout and the objectives of data scraping projects, they can create powerful synergies that lead to successful outcomes.
Key strategies for enhancing collaboration include:
Transparent Communication: Establish open lines of communication to ensure both parties understand their goals and challenges.
Shared Documentation: Utilize shared documents or platforms to keep track of updates in website structure, which can impact scraping methods.
Regular Feedback Loops: Implement scheduled check-ins to assess progress, troubleshoot issues, and adapt strategies accordingly.
Data Accessibility Considerations: Developers can assist in structuring HTML and APIs to allow for easier data access.
Consider the importance of website structure. When developers prioritize semantic HTML and logical content hierarchies, they create a foundation that not only supports user experience but also enhances data scraping effectiveness. A well-structured site with clear tags and organized content allows scrapers to navigate effortlessly, reducing errors and improving data accuracy.
Furthermore, aligning the objectives of developers and data scientists can lead to innovative strategies for data retrieval. For instance, implementing specific markup standards like Schema.org can improve the discoverability of data. This not only elevates the site’s SEO but also directly benefits scraping efforts by making the data more accessible and easier to parse.
Website Structure Element
Impact on Data Scraping
HTML Tags
Facilitate targeted scraping of specific content.
URL Structure
Supports systematic crawling and data collection.
JSON-LD Markup
Enhances data visibility for scrapers and APIs.
Ultimately, the success of data scraping projects hinges on structured collaboration between developers and data professionals. By fostering a culture of teamwork, sharing knowledge, and actively working to enhance website architecture, teams can unlock the true potential of data scraping. It’s a journey of innovation that promises not just efficiency but also quality and accuracy in the data-driven decisions of tomorrow.
Conclusion: Building a Strong Foundation for Data Scraping Excellence
In the realm of data scraping, success hinges on a well-structured approach that appreciates the intricacies of website architectures. A proficient scraper recognizes that the foundation laid during the planning phase dictates the efficacy and efficiency of the entire project. By understanding the various elements of website structures, one can unlock a treasure trove of data that is both valuable and actionable.
To achieve excellence in data scraping, consider the following key principles:
Analyzing Website Layouts: Before launching a scraping project, a thorough analysis of the target website’s layout is vital. This includes understanding the HTML hierarchy, CSS selectors, and JavaScript functionalities that may influence data retrieval.
Implementing Robust Tools: Selecting the right tools and libraries can make all the difference. Tools like Beautiful Soup, Scrapy, or Selenium are designed to navigate complex structures effectively, ensuring that data extraction is seamless.
Adapting to Changes: Websites are not static; they evolve over time. Building a system that can adapt to these changes—such as employing dynamic scraping techniques or incorporating error handling—is essential for long-term success.
Respecting Ethical Guidelines: Adhering to ethical scraping practices not only protects your project from legal repercussions but also fosters goodwill with the websites you are targeting. This includes understanding and respecting robots.txt files and terms of service.
Furthermore, the implementation of a structured data extraction process can significantly enhance productivity. By categorizing data into relevant segments, you can streamline the scraping process and make the data more manageable. Consider the following table that outlines a simple categorization strategy:
Data Type
Example
Importance
Textual Content
Product Descriptions
High
Metadata
Page Titles
Medium
Images
Product Images
High
Links
Related Products
Low
By adopting these strategies, you not only enhance the quality of your data scraping projects but also lay a strong foundation for future endeavors. The journey of mastering data scraping is ongoing; each project offers a chance to refine your skills and methodologies. Thus, with a well-thought-out plan and the right tools at your disposal, the possibilities for data extraction are endless.
Ultimately, the key to thriving in the world of data scraping lies in continuous learning, adaptation, and ethical practices. As you build upon your successes and learn from your challenges, you’ll find that your expertise will grow, leading to more refined strategies and superior outcomes in your data scraping initiatives.
Frequently Asked Questions (FAQ)
Q&A: How Website Structures Impact the Success of Data Scraping Projects
Q1: What is the significance of website structure in data scraping projects? A1: The structure of a website plays a crucial role in the success of data scraping projects. A well-organized website with a clear hierarchy and consistent HTML structure allows scrapers to navigate and extract data efficiently. In contrast, poorly designed websites can lead to data extraction challenges, inconsistencies, and increased development time. By understanding and leveraging website structures, data scrapers can unlock invaluable insights and drive impactful results.
Q2: How does a clean URL structure benefit data scraping? A2: Clean and logical URL structures not only enhance user experience but also simplify the process for scrapers. When URLs are descriptive and organized hierarchically, it becomes easier to identify patterns and navigate the site programmatically. This clarity reduces the complexity of scraping logic, resulting in more efficient data extraction and a higher success rate for your projects.
Q3: What role do HTML elements and tags play in the scraping process? A3: HTML elements and tags are the backbone of any website’s content. When structured thoughtfully, they provide clear markers for scrapers to identify and extract relevant data. For instance, using appropriate semantic tags (like
, , and ) allows scrapers to pinpoint headings, subheadings, and paragraphs seamlessly. This organized approach not only boosts data accuracy but also enriches the quality of insights derived from the scraped data.
Q4: Can you explain the impact of dynamic content on data scraping? A4: Dynamic content, often generated by JavaScript, presents unique challenges for data scraping. Websites that rely heavily on JavaScript can hide crucial data from scrapers that only read static HTML. Understanding the website’s structure helps scrapers devise strategies—like simulating browser behavior with headless browsers or utilizing APIs—to access this dynamic content. Embracing these techniques can elevate your scraping projects, transforming hurdles into stepping stones.
Q5: Why is it important to consider website responsiveness in scraping? A5: With the vast array of devices used to access websites today, responsive design ensures that content is displayed appropriately across different screen sizes. For data scraping, this means that the data layout might change based on the device. Being aware of this can help scrapers adapt to various formats, ensuring they consistently extract the right data regardless of how the website is displayed. A flexible approach to scraping can lead to more comprehensive data sets that reflect true user experiences.
Q6: What are some best practices for structuring scraping projects to accommodate diverse website structures? A6: To navigate the diverse landscape of website structures, consider implementing these best practices:
Conduct thorough site mapping: Before scraping, analyze the website’s structure to identify key data points and their locations.
Use robust libraries and frameworks: Leverage tools like Beautiful Soup, Scrapy, or Selenium that offer flexibility in handling various HTML structures and dynamic content.
Build in adaptability: Design your scraping scripts to be adaptable to changes in website structure, allowing for easy updates when necessary.
Implement error handling: Anticipating structural inconsistencies can save time and ensure your scraping processes remain robust.
Q7: How can understanding website structures inspire innovation in data scraping? A7: By grasping the intricacies of website structures, data professionals can unlock new avenues for innovation. This knowledge encourages creative approaches to data extraction, leading to enhanced techniques, the development of custom scraping solutions, and even the creation of new data-driven products. When you align your scraping strategies with the architecture of the web, you empower your projects to reach their fullest potential, transforming raw data into meaningful insights that can inspire action.
Q8: what is the key takeaway regarding website structures and data scraping success? A8: The key takeaway is that understanding website structures is not just an optional skill for data scrapers; it is a vital ingredient for success. By appreciating how website design impacts data accessibility and crafting your scraping strategies accordingly, you can turn challenges into triumphs. Embrace the learning journey, harness the power of structured data, and watch your scraping projects soar to new heights of success!
In Conclusion
the structure of a website is not merely a technical detail; it’s the very backbone of successful data scraping projects. By understanding and leveraging the nuances of web architecture, you can transform challenges into opportunities. The insights gleaned from a well-structured website can propel your data scraping endeavors from mere extraction to insightful analysis, ultimately driving better decision-making and innovation in your organization.
As you embark on your data scraping journey, remember that every website holds valuable information waiting to be uncovered. Embrace the power of structured data, and let it guide you toward success. With the right approach, the complexities of web structures can become your allies, enabling you to harness data like never before.
So, be bold, be curious, and let the synergy between thoughtful web design and strategic data scraping lead you to new horizons. The future of data is not just about what you scrape, but how you navigate the intricate web of information that surrounds you. Together, let’s unlock the potential that lies within, turning raw data into transformative insights that inspire action and drive progress.
In today’s rapidly evolving digital environment, remote desktop protocol (RDP) hosting services are more than just a luxury—they’re a necessity for businesses, freelancers, gamers, marketers, and developers seeking speed, security, and scalability. Among the most well-known providers in the industry, AmazingRDP has carved out a reputation for delivering performance-oriented RDP solutions that cater to a wide variety of users worldwide.
After thoroughly examining every aspect of Spinservers.com—from performance and pricing to customization and customer feedback—we confidently conclude that Spin Servers is absolutely worth it for the right kind of user.
This is not your average “beginner-friendly” hosting provider. Spin Servers is engineered for developers, sysadmins, SaaS startups, streaming platforms, and digital businesses that need unthrottled, high-performance infrastructure without bloated pricing or unnecessary hand-holding.
Are you on the hunt for the perfect web hosting solution that won’t break the bank? Look no further! Today, we’re diving into an in-depth review of Alexhost.com, a rising star in the world of web hosting. Whether you're a budding entrepreneur, a seasoned developer, or someone just looking to set up a personal blog, finding a reliable hosting provider is crucial. But with so many options out there, how do you know which one to choose? That’s where we come in! In this article, we'll explore the features, benefits, and potential drawbacks of Alexhost.com, helping you decide if it's the right fit for your online needs. So grab a cup of coffee, sit back, and let’s unravel what makes Alexhost.com a contender in the hosting arena!
Are you on the hunt for a reliable web hosting provider that won’t break the bank? If so, you’ve likely stumbled across Dedicated.com, a company that promises performance, flexibility, and customer support that’s second to none. But does it really deliver on these promises? In this article, we’ll dive deep into a comprehensive review of Dedicated.com, exploring its features, pricing, customer service, and much more. Whether you’re a seasoned web developer or just starting your online journey, we’ve got the inside scoop to help you decide if this hosting solution is the right fit for your needs. So, grab a cup of coffee, and let’s unravel the truth behind Dedicated.com!
If you’re on the hunt for reliable web hosting, you’ve probably come across Hostinger in your research. But is it really the best choice for you? With so many options available, it’s easy to feel overwhelmed. That's where we come in! In this review, we’ll dive deep into what Hostinger offers, from its pricing and performance to customer support and user experience. Whether you’re a blogger, a small business owner, or a budding entrepreneur, we aim to give you the insights you need to make an informed decision. So grab a coffee, settle in, and let’s explore whether Hostinger is the web host that can elevate your online presence!